
Decoding UTF-8. Part V: Benchmarking Sequence Length Calculations
Measuring throughput of some methods for determining UTF-8 sequence lengths

In Parts II, III, and IV of this series on decoding UTF-8, we examined several methods for determining the length of a UTF-8 encoded byte sequence. We presented the algorithms and inspected the generated assembly, but we did not measure performance. In this post we run simple tests to compare the throughput of the three methods.
Test Descriptions
To recap, the three methods we compare here are:
The “bitmask” method, described in Decoding UTF-8. Part II: Determining Sequence Length - a Straightforward Approach:
int utf8_sequence_length(unsigned char lead_byte) {
if ((lead_byte & 0x80) == 0) {
// Single byte (0opqrstu)
return 1;
} else if ((lead_byte & 0xE0) == 0xC0) {
// Two-byte sequence (110xxxxx)
return 2;
...
}The “lookup” method, described in Decoding UTF-8. Part III: Determining Sequence Length - A Lookup Table:
int utf8_sequence_length(unsigned char lead_byte) {
// Hard-coded lookup table for UTF-8 lead byte lengths
static const unsigned char lookup[256] = {
...
};
// Access the hard-coded table to determine the sequence length
return lookup[lead_byte];
}The “countlz” method, which uses hardware support for counting leading zeros in a byte, described in Decoding UTF-8. Part IV: Determining Sequence Length - Counting Leading Bits:
int utf8_sequence_length(unsigned char lead_byte) {
switch (std::countl_one(lead_byte)) {
case 0: return 1;
case 2: return 2;
case 3: return 3;
case 4: return 4;
default: return 0; // invalid lead
}
}There are two sets of data in the test:
Pure ASCII text.
Cyrillic text with ASCII HTML tags.
I used two different compilers:
Clang 18.1.3
GCC 13.3.0
The results presented in this article were obtained on a Microsoft Surface laptop with a Snapdragon X1E80100 12-core CPU @ 3.40 GHz and 16 GB RAM, running Ubuntu 22.04 under WSL 2.
The code for the benchmarks can be found at: https://github.com/nemtrif/utfbench/tree/main/seqlen
My expectations based on the generated assembly were:
For the ASCII text, I expected the straightforward “bitmask” method to perform best, as the data is very friendly to branch prediction, and the branch executed is very efficient. I expected the “countlz” method to perform somewhat worse, and the “lookup” method to perform worst.
For the ASCII/Cyrillic mix, I thought branch prediction would be much less effective and the branchless variants would perform better. I expected “countlz” to be fastest, followed by “lookup”.
Let’s see how good my predictions were.
Clang 18.1.3 Results
The code was compiled with:
clang++ -O2 --std=c++20The results for ASCII text are:
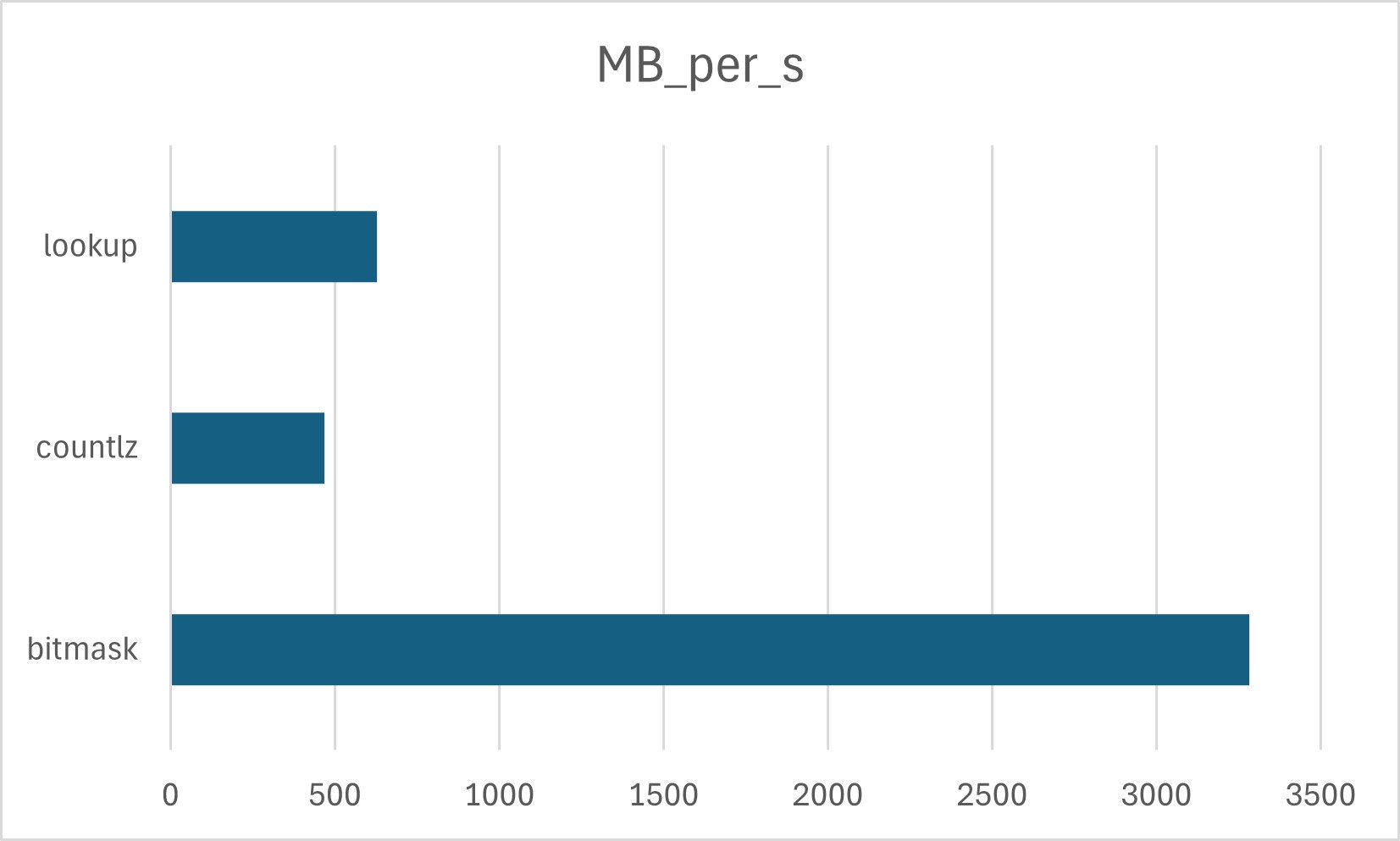
I did expect the “bitmask” version to perform best. For ASCII text the hot path executes a TBNZ that checks the highest bit, sets the return value to 1, and jumps to the function epilogue (assuming the function is not inlined). That said, the sixfold difference between the bitmask and table-based methods was surprising.
The same setup but with Cyrillic HTML produced the following results:
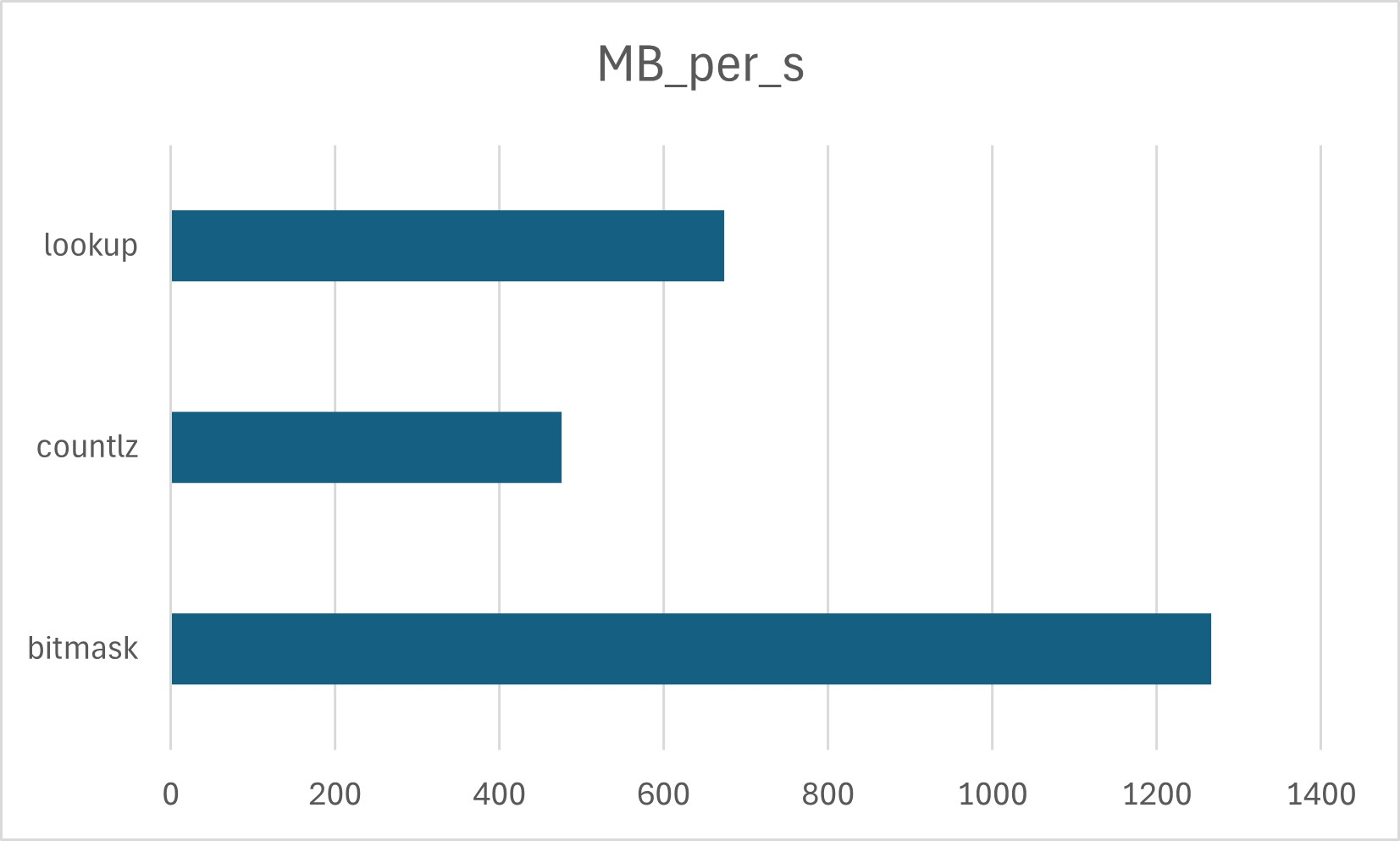
I expected the mix of Cyrillic and ASCII characters to confuse the branch predictor, and it did, but the “bitmask” method was still twice as fast as the “lookup” method. The “countlz” method performing worst was definitely a surprise given the small size of the compiler-generated lookup table and the hardware-assisted bit counting.
GCC 13.3.0 Results
The code was compiled with:
g++ -O2 --std=c++20The results for ASCII text:
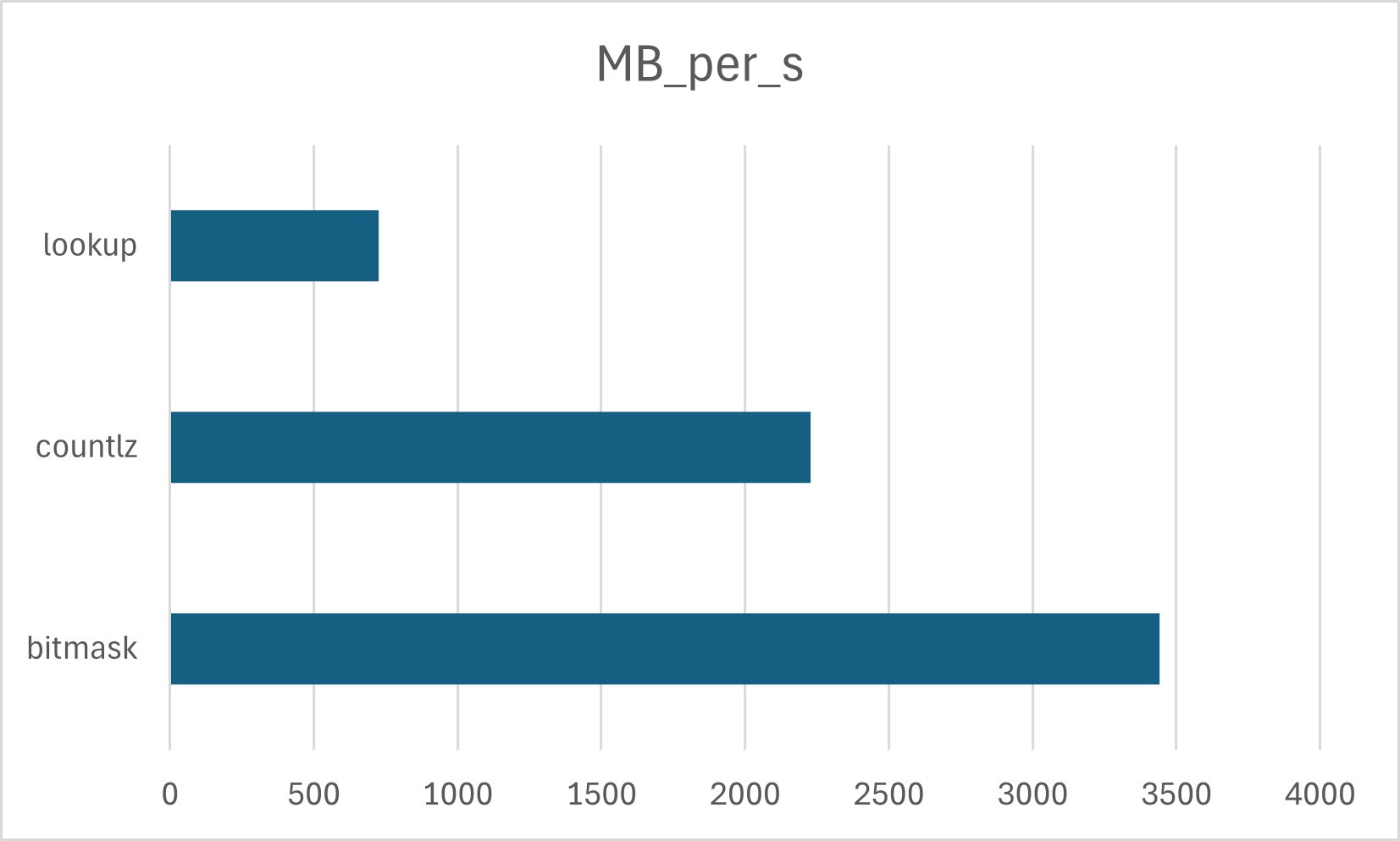
The only noteworthy difference between these results and Clang’s is the performance of the countlz method, which processed almost five times more data when compiled with GCC. The detailed explanation can be found in my recent article When Compiler Optimizations Hurt Performance where we saw how a compiler-generated lookup table meant to optimize switch-case statements actually hurt performance. GCC did not perform the optimization and that is the reason it produced better code.
Benchmark with Cyrillic HTML produced the following results:
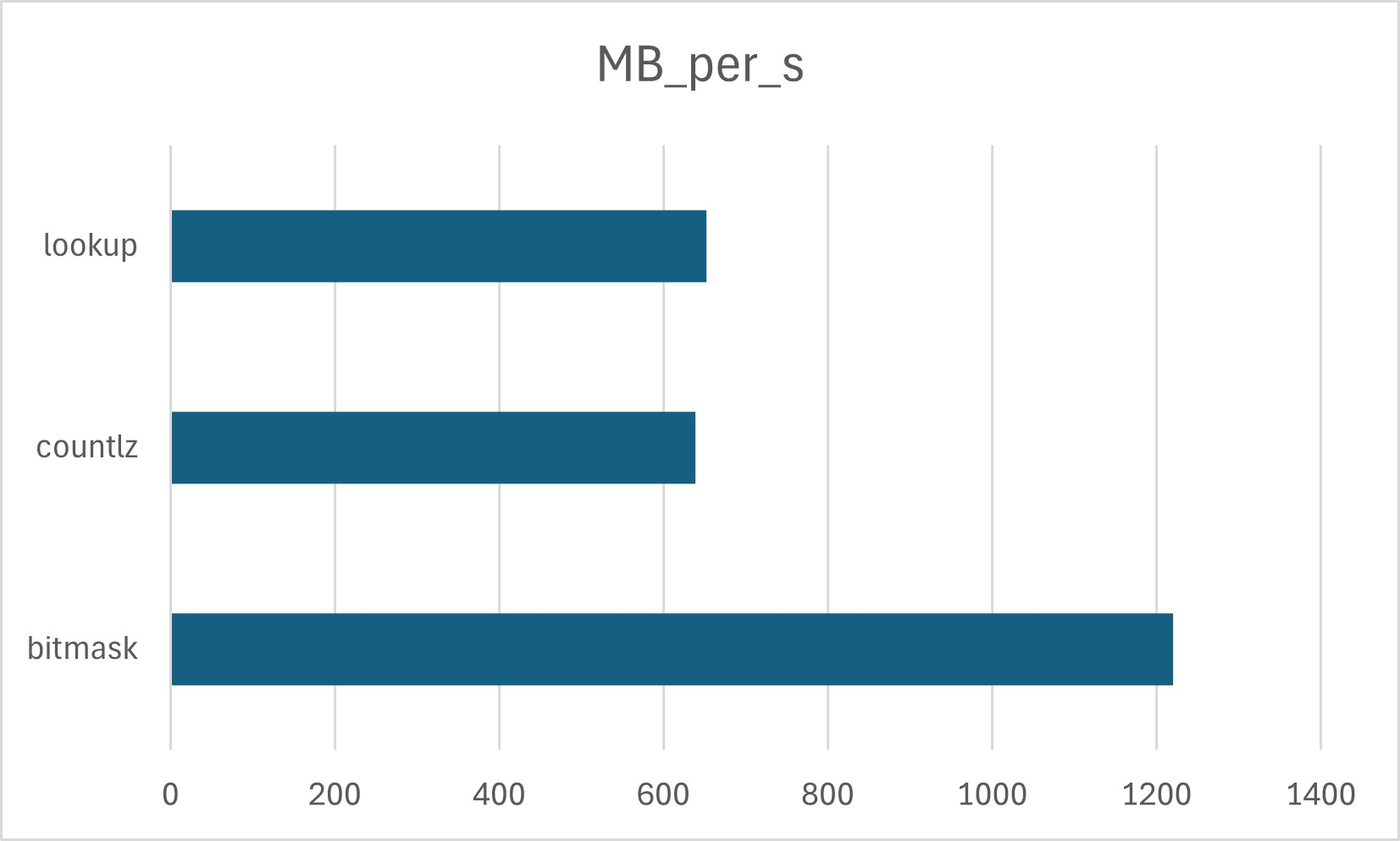
There is little difference between GCC and Clang. The “countlz” method was hurt by branches and it ended up being roughly equivalent to the lookup method.
Conclusion
If there is a conclusion to be made from this exercise, it is to be very careful about avoiding branches by creating lookup tables - either manually or via compiler optimizations.
The boring, straightforward “bitmask” method easily won, even when data was not helping the branch predictor. Memory access turned out to be more expensive even without any cache misses.